

개요


Spring Data JPA가 제공하는 JPARepository 인터페이스는 PagingAndSortingRepository와 CrudRepository, Repository 인터페이스를 차례로 상속받는데, 그 중에서 페이지네이션을 지원하기 위한 repository가 PagingAndSortingRepository이다. PagingAndSortingRepository를 보면 Pageable 타입을 인자로 받고, Page타입을 반환하는 findAll() 추상메소드가 존재하는 것을 볼 수 있다.


여기서 인자로 넘어오는 Pageable 인터페이스는 페이지 번호, 페이지 크기, 정렬순서와 같은 정보들을 갖고 있으며, PageRequest의 of()라는 정적 팩토리 메소드를 통해서 Pageable 인터페이스를 구현한 PageRequest 타입의 객체를 생성할 수 있다.

위에서 설명한 Pageable타입의 객체를 인자로 하여 넘겨주면 Spring Data JPA의 PagingAndSortingRepository를 이용해서 페이지네이션을 사용할 수 있다. JPA에서 지원하는 페이지네이션 방법은 크게 두 가지로 분류해볼 수 있는데, Page와 Slice이다.
Page 간단 소개

일반적으로 offset을 이용한 페이징을 위해서 사용되는 객체이다. (단, Page라고 무조건 offset방식의 페이징을 의미하는 것은 아닌듯 하다.) 이때 offset방식 페이징이란 쿼리문에서 조회를 시작할 기준점을 설정하는 것을 의미한다.
Page는 객체 안에 현재 페이지의 데이터와 전체 페이지 수와 같은 정보를 포함하고 있기 때문에 반환 리스트의 element들을 일정 개수(size)만큼 노출시키고, 페이지 번호(page)를 통해서 원하는 결과가 포함된 리스트로 바로 이동할 수 있다.

참고로 Page는 후술할 Slice 인터페이스를 상속받고 있기 때문에 Slice에서 사용되는 모든 메서드는 Page가 동일하게 사용할 수 있다.
Slice 간단 소개

Slice는 페이징된 데이터의 마지막 id값을 기준으로 다음 데이터를 조회하는 커서 기반 페이지네이션 방식이며, 페이지마다 현재 페이지의 정보와 다음 페이지에 대한 정보(다음 페이지가 존재하는지 여부)가 담겨 있다. 가장 대표적인 예시가 앱에서 무한 스크롤을 구현할때 많이 쓰인다.
Page와 Slice - Tradeoff
그렇다면 한쪽 방향으로만 조회가 가능한 Slice보다는 방향성에 있어서 제약을 덜 갖는 Page가 낫지 않을까? 라는 생각이 들수도 있다.
하지만 Page는 Slice와 다르게 전체 데이터의 개수를 파악하는 과정이 필요하기에 count 쿼리가 한번 추가로 나가는데, 데이터베이스 엔진이 캐시를 이용하는 등의 방법으로 최적화되어있는 특별한 경우가 아니라면 모든 데이터에 대한 조회가 이루어지게 되어 O(N)의 시간복잡도를 가지게 된다. 따라서 Slice를 사용하는 것보다 Page를 사용하는 것이 성능적으로는 손해일 수 있다.
또한, offset 방식의 페이징은 offset을 계산하여 데이터베이스에 쿼리를 날리는 방식을 사용하며, 페이지 번호(page), Page 객체에는 한 페이지에 불러올 데이터 건수(size, limit), 정렬 조건(sort)과 같은 정보들이 들어갈 수 있다. 이렇게 offset을 사용하는 방식은 offset까지의 데이터를 모두 읽게 만들기에 O(N)의 조회 비용을 가져 성능 저하가 발생할 수 있다.
간단하게 PagingAndSortingRepository의 메소드를 테스트해보았다. BaseTest에서 @SetUp으로 5명의 User를 insert해준 뒤, 다음과 같은 테스트를 돌려보았다.
public class PageSliceTest extends BaseTest{
private final int PAGE_SIZE = 2;
private final String sortStd = "id";
@Test
@DisplayName("Page, Slice 쿼리 테스트")
public void pageSliceTest() {
// Pageable pageable = PageRequest.of(1, PAGE_SIZE);
Pageable pageable = PageRequest.of(1, PAGE_SIZE, Sort.by(sortStd));
Page<User> pageBy = userRepository.findPageBy(pageable);
Slice<User> sliceBy = userRepository.findSliceBy(pageable);
}
}
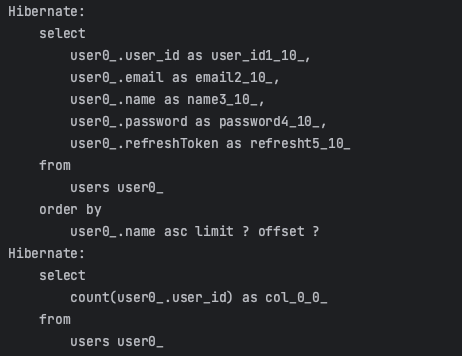

Page로 조회해올 때 Slice보다 count쿼리 하나가 더 나가는 것을 확인할 수 있었다. db 전체 데이터를 한번 스캔해야 하니 시간이 더 걸릴 수 밖에 없다. 심지어 count(*)가 아니라 count(user.id)로 조회하는 것을 보아 쿼리 최적화가 되지 않은 모습도 확인할 수 있다.
추가로 해볼 수 있는 고민들
1. Slice와 no-offset
Slice와 no-offset을 구분하자.
SELECT *
FROM 테이블
WHERE 조건문
ORDER BY id DESC
OFFSET 페이지번호
LIMIT 페이지사이즈
기존 방식인 offset과 limit을 사용한 페이징 쿼리의 예시이다. 그런데 이와 같은 형태의 쿼리로 페이징을 진행하면 앞에서 읽었던 행들을 다시 읽어야 하기 때문에 offset이 증가할수록 탐색속도가 느려진다는 문제가 발생한다. 따라서 대신 사용하는 방법이 클러스터 인덱스인 PK를 조건문에 붙여서 인덱스 단위로 빠르게 조회하는 no-offset 페이징이다.
SELECT *
FROM 테이블
WHERE 조건문 AND id < lastId
ORDER BY id DESC
LIMIT 페이지사이즈
처음과 다르게 offset쿼리가 없어지고, 조건문에 pk제약을 붙은 모습을 확인할 수 있다.
위와 같이 성능상의 이유로 무한스크롤을 구현할 때 일반적으로 no-offset방식의 페이징을 사용하고, Slice가 no-offset 페이지의 대표적인 예시라고 알고 있었는데, 위에서 로그로 찍힌 Slice 쿼리를 보니 여전히 offset쿼리가 포함되어 나가는 것을 확인할 수 있었다.
사실 Slice는 일반적으로 no-offset방식으로 페이징하지만, Spring Data JPA 메소드에 Slice를 전달하는 것 자체로는 no-offset을 지원하지 않는다. no-offset 방식의 페이징을 위해서는 Querydsl 등의 방법을 통해 아래와 같이 offset쿼리를 직접 제거해주어야 한다.
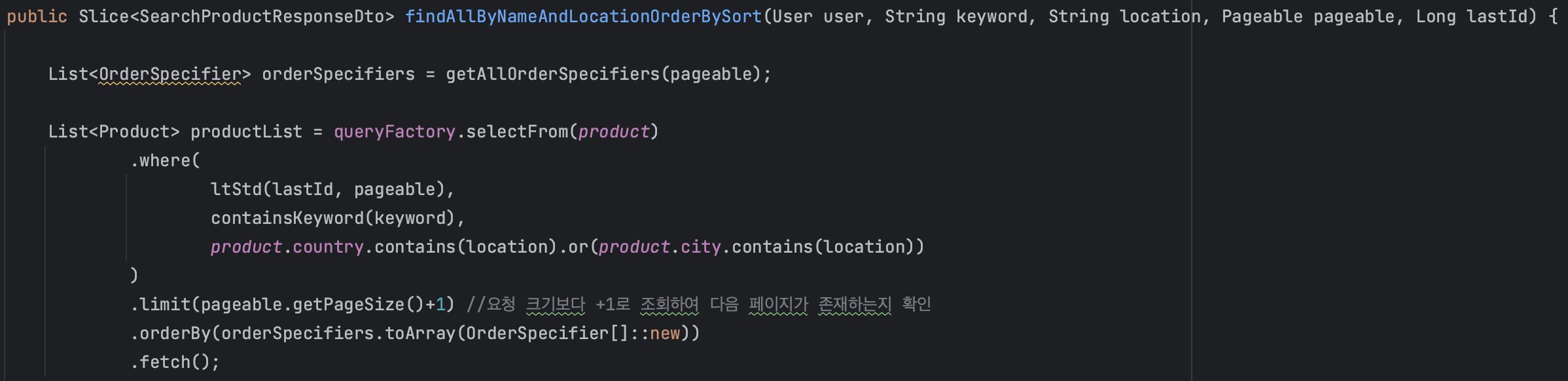
2. 데이터 중복이나 손실
또한 offset방식을 사용한 방식은 조회 중에 새로운 데이터가 추가되면 데이터가 중복되어 표시되거나, 누락되는 현상이 발생할 수도 있다. 간단하게 데이터베이스에 3개의 데이터가 존재한다고 가정하자.
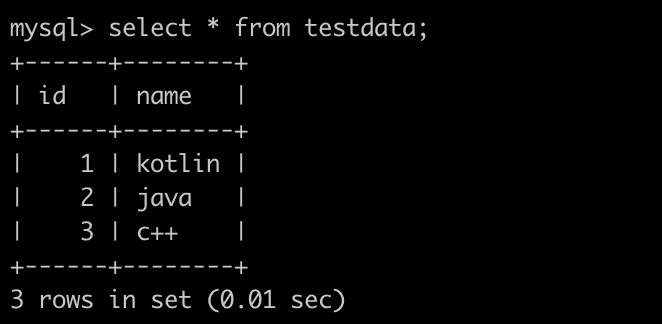
testdata 테이블에 다음과 같은 3개의 데이터가 들어있고, 최근순 정렬로 2개씩 페이지네이션을 진행한다고 가정하자. 첫 페이지에는 (3, c++)과 (2, java)가 노출될 것이다. 이 상태에서 무한 스크롤을 통해서 한 페이지를 더 조회하면 (1, kotlin)이 노출되기를 기대하고 있을 것이다.

하지만 첫 페이지를 조회한 직후 (4, ada)라는 데이터가 추가되었다고 가정하면, 두번째 페이지를 출력하기 위해서 요청을 보냈을 때는 (2, java)와 (1, kotlin)이 나오게 된다. 추가한 (4, ada) 데이터가 최근순 정렬을 하고 나니 첫 번째 페이지에 들어가버리고, 첫번째 페이지에 나온 (2, java)가 두번째 페이지에도 나와버리는 문제가 발생한 것이다. 따라서 새로운 데이터가 추가될 경우 이를 처리하거나, 페이지 번호와 관련된 정보를 유지하면서 조회를 진행해야 한다.
이를 해결하기 위해서는 커서를 사용한 no-offset방식의 페이징을 진행해서 해결할 수 있다. 정렬 기준이 시간 내림차순이라면 단순히 커서를 id나 timestamp로 잡아주면 되기 때문이다.
(나도 infinity scroll을 위한 Slice 사용중 위와 같은 문제가 발생한 적이 있는데, 내가 사용했던 방법은 첫 조회시점 이후에 추가된 데이터는 리스트에서 제외하는 방법이었다. 무조건 최신순으로 정렬한다는 비즈니스적 합의 이후에 lastId라는 기준을 두어 '어디부터 출력하면 되는지'를 알 수 있게 하였다. 일종의 책갈피 역할을 한다고 생각하면 될 것 같다.)


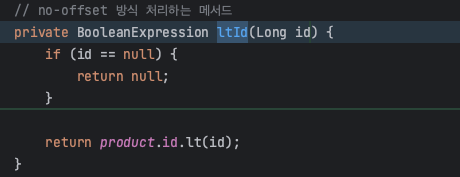
위 예시가 pk를 사용한 no-offset방식의 페이징이다. lastId라는 쿼리파라미터를 사용하였는데, 처음 요청시에는 lastId를 보내지 않는다. 그러면 ltId() 메소드에서는 BooleanExpression의 리턴값이 null이 되어 조건이 없이 모든 product에 대해서 조회하게 된다. 그 다음에 클라이언트는 반환받은 값중 가장 id가 작은 product의 id를 lastId에 넣어 보낸다. 그러면 그 id보다 1 작은 product부터만 조회하여 페이지네이션을 진행하게 되고, 데이터가 밀리거나 중복되는 현상은 일어나지 않는다.
추가로 infinity scroll방식이 아닌, Page방식의 페이지네이션의 경우는 이전 페이지의 element가 더 이상 표시되지 않기에 같은 데이터가 다른 페이지에 각각 한번씩 표시되더라도 비즈니스적으로 문제가 되지 않을 여지가 높아서 고려하지 않았다.
3. 정렬조건이 추가로 붙으면..
하지만 최신순 데이터가 아니라, 정렬을 요구하는 데이터라면 또 이야기가 달라진다. 예를 들어, 위에서 최신순이 아니라 좋아요가 많은 순서대로 출력하기를 요구받았다고 하자. 이제는 id가 아니라 product의 좋아요 수를 기준으로 출력해주어야 하기 때문에, lastId 대신 lastLikeCount와 같은 다른 조건의 기준점을 사용해야 한다. 대신 이제는 lastId를 사용함으로서 예방했던 신규데이터 추가를 방지할 수 없다.
첫 번째 아이디어
신규데이터 추가를 아예 방지하면 된다. 첫 요청시 서버로 lastId가 null로 들어오면 첫 요청에 lastId를 세팅해서 보내주고, 그 이후로는 lastId를 계속 주고받으면서 where조건으로 처음 조회 시점 이후의 데이터가 조회되지 않게 설정할 수 있다. 문제는 1. 쿼리 where절에 고정 조건이 추가되어 성능 저하가 있을 수 있고, 2. 검색조건을 초기화(lastId=null)하기 전에는 새로운 데이터는 표시되지 않는다는 문제가 존재한다. 또한 클러스터 인덱스를 활용할 수 없으므로 pk로 no-offset 페이징을 하는 것보다는 속도가 훨씬 느리다.
두 번째 아이디어
첫 번째 아이디어와 동일하게 lastId를 사용하되, 정렬조건을 unique한 컬럼으로 한정하고 해당 컬럼을 대상으로 인덱스를 생성해준다. 그러면 꼭 pk가 아니더라도 논클러스터링 인덱스를 사용하여 효율적인 no-offset방식의 페이징이 가능해진다. 물론 unique한 컬럼으로 정렬조건이 한정된다는 단점이 있지만, pk를 제외한 다른 컬럼으로도 인덱스를 활용하여 데이터베이스의 읽기 성능 저하를 막을 수 있다.
4. (쓸데없는 고민) 그런데 no-offset이 무조건 더 빠를까?
대규모 데이터셋의 경우 당연히 인덱스를 활용한 no-offset 페이징이 빠르겠지만, 데이터가 적어 인덱싱을 활용한 조회가 성능에 크게 영향을 끼치지 않는다면 no-offset이 무조건 빠르다고는 장담할 수 없다. 데이터가 적은 경우 성능차이가 미미하고, 오히려 과한 인덱스 생성으로 인해 너무 많은 컬럼에 인덱스가 생성되는 상황이라면 인덱스 부하(추가적인 저장공간이 필요하고, 데이터의 변경에 따라 인덱스도 업데이트되어야 하니)로 인한 overhead도 존재하기 때문이다. 다만 개발의 방향성은 항상 worst-case로 잡는 것이 맞으므로 no-offset 페이징을 꺼릴 필요는 없겠다.
참고자료: count(*)와 count(user.id)의 성능차이
'[ Backend ] > Spring DB, JPA' 카테고리의 다른 글
| [Spring DB] 트랜잭션 매니저 커스텀하기 (0) | 2024.04.25 |
|---|---|
| [Spring Data JPA] @Repository를 생략해도 되는 이유 (0) | 2023.12.10 |
| [JPA] N+1 문제 (0) | 2023.07.11 |
| [Spring DB] 스프링과 트랜잭션, 트랜잭션 전파 (0) | 2023.07.02 |
| [JPA] 쓰기 지연으로 인한 서비스 오류 경험 (0) | 2023.06.21 |