[컴퓨터구조] Cache Memory - Direct Mapped Cache
- [ CS기초 ]/컴퓨터구조
- 2021. 11. 20.
0. 캐시 메모리란? 그 필요성
메모리를 계층적으로 재구성하여 빠르고 큰 메모리인것처럼 Processor(CPU)를 속이는 것.
일반적으로 빠른 메모리는 비싸고 크기가 작고, 느린 메모리는 싼 대신 크기가 크다.
빠른 메모리를 프로세서 가까이에, 느린 메모리는 그 밑에 계층적으로 배치하고, 데이터 지역성을 활용하여 효율적인 메모리 구성이 가능하도록 한다.
데이터 지역성
- 시간 지역성
- 한번 참조된 데이터는 곧 재참조될 가능성이 높다는 것을 의미. loop문을 생각해보면 이해가 편하다.
- 공간 지역성
- 배열구조처럼 같은 데이터 배열에 연속적으로 접근할때 참조된 데이터 근처에 있는 데이터가 재참조될 가능성이 높음을 의미.
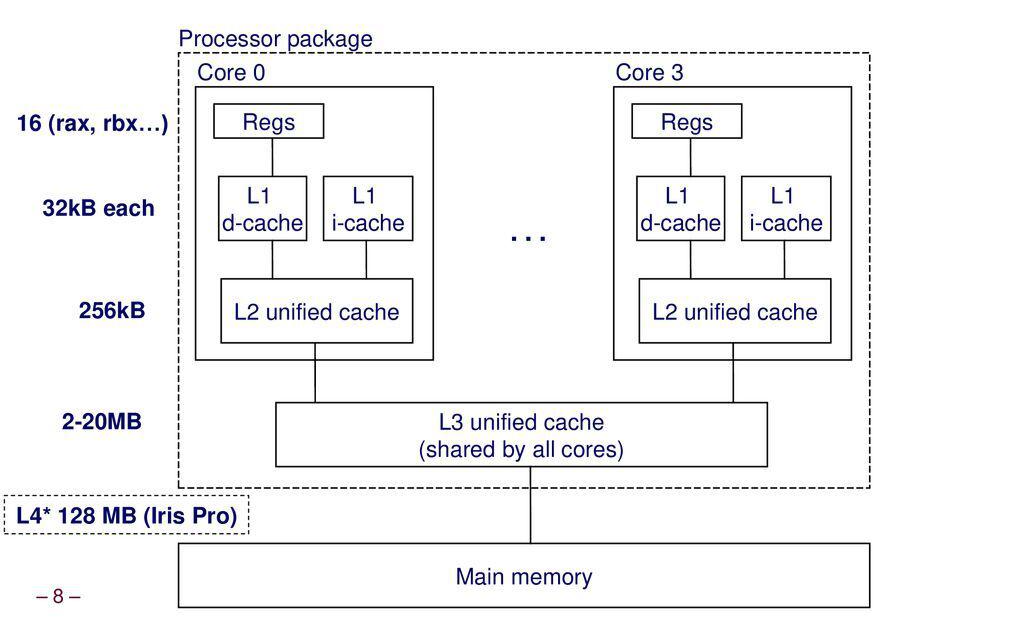
-Block : 데이터 전달의 최소단위.
-Hit : CPU가 원하는 데이터가 상위계층에 존재.
-Miss : CPU가 원하는 데이터가 상위계층에 존재하지 않음
-Hit time = Hit이 될때 필요한 처리시간
-Miss penalty = Miss가 발생했을때, Hit time에 추가로 소요되는 시간.
-AMAT (Average Memory Access Time) : hit time + miss rate*miss penalty
> 상위계층 접근에 걸리는 필수 소요시간 + miss시 추가로 소요되는 시간
+ Multi level inclusion property : 상위계층에 존재하는 것은 하위계층에도 존재한다는것을 전제하겠다. (opp. -exclusion - )
1. Set-associative Cache ( n-way set associative cache )
캐시 접근의 기본이 되는 방법이다. 후에 서술할 Directed Mapped Cache와 Fully associated Cache 모두 이 방법의 확장이라고 생각하면 된다.
기본적으로 캐시 메모리는 프로세서가 원하는 데이터를 메모리에서 찾아주는 과정에 사용되는데, 단순하게 Processor-Memory 구조로 이루어져 있다면 메모리의 속도가 프로세서의 속도를 따라잡지 못해서 프로세서 동작이 많이 느려질 것이다. 이러한 단점을 위에서 설명한 데이터 지역성을 이용하여 극복할 수 있다.
프로세서가 메모리에 데이터를 요구하면, main메모리에 바로 접근하기 전에 캐시 메모리에 데이터 존재 여부를 확인한다. 이때 CPU가 보내는 메모리주소에서 하위 N비트를 잘라서 캐시주소로 사용하는 방식을 취한다.
1-1. Direct Mapped Cache ( = 1-way set associative cache )
Direct-Mapping을 사용하여 cache memory address를 바로 구할 수 있다
여기서 Direct-mapping이란 메인메모리의 주소를 보고 캐시메모리의 주소를 직접 바로 알 수 있음을 의미한다.

- 메인메모리의 주소를 보고 캐시메모리의 주소를 알 수 있는 방법
간단하게 메인메모리의 주소를 Tag/Index/Offset으로 분리하여 해당 부분을 캐시메모리에 저장한다.
이때 Index를 이용해 캐시메모리의 어디에 들어가 있는지를,
Tag를 이용해 캐시메모리에 존재하는 데이터가 내가 찾고 있는 데이터인지를 구별한다.
<용어>
- Valid bit(1) : 쓰레기값을 구별해주는 비트. 0이면 메모리 내 데이터가 유효하지 않음(쓰레기값을 가지고 있다)을 나타내준다.
- Data : 메모리 내 데이터. 데이터의 크기를 Block Number라고 한다. (ex. 2^m-word block : 2^(m+2)B)
- Tag : 원래 존재하던 위치를 식별하기 위해서 사용하는 상위비트.
- Index(2^n) :
- Cache size : 캐시 메모리의 데이터 부분의 크기만을 의미.
캐시메모리의 크기, block의 개수, block의 크기는 다음과 같은 관계식을 갖는다
> number of blocks = cache size / block size
cache size = number of blocks * block size
따라서 캐시의 크기라는 것은 block의 데이터부분 사이즈만을 의미한다는 사실도 알 수 있다.
+ Total number of bits of cache = (index의 개수) * {valid bit + block size) >>>> 캐시가 차지하는 비트크기와 캐시의 크기는 다르다(적고보니 말장난같긴 한데,,)
- Cache with 1-Word blocks
직역하면 1-word block들로 이루어진 캐시를 의미한다. 여기서 캐시가 1-word block들로 이루어져 있다고 하는 것은 캐시의 1행(=block)의 데이터부분의 크기가 1-word(4B)이라는 것을 말한다. 메모리에서 word addressing을 통해 32bit=4B=1word 단위로 데이터를 전달하므로 캐시의 데이터 단위를 word로 설정하면 사용에 용이하다.

32bit 컴퓨터 기준 메인 메모리에서 8bit 4개를 묶어서 32bit(=4B)씩 읽어오는데, 그러한 모습을 나타낸 사진이다. 4B의 메모리가 하나의 태그로 묶여 인덱스에 저장되고 있다. 그러면 당연히 캐시에도 4B씩 저장해야 되고, 그래서 Cache의 데이터 크기가 4B가 되므로 'Cache with 4-byte blocks' 이나 'Cache with 1-word blocks'라고 말하는 것이다.
또한 위 사진의 메인메모리 부분을 보면 알 수 있듯이, word 1개당 메인 메모리의 주소값이 4개씩 묶이므로 ...XXXX00~XXXX11까지 4개의 메모리 주소가 하나로 묶여 들어가기 때문에 2비트의 offset을 설정할 수 있다. 이것을 정리하면
캐시메모리의 데이터부분 크기가 2^m이고, index가 2^n개일때 (block의 개수가 2^n개라고 나는 이해했다) offset은 m개를 가진다. 라고 정리할 수 있다.
마지막으로 tag는 메인메모리 주소에서 index와 offset을 제외한 나머지 상위비트를 전부 tag로 설정한다. 따라서 index와 tag를 알면 둘을 조합하여 찾는 메모리의 범위를 알 수 있다.

'[ CS기초 ] > 컴퓨터구조' 카테고리의 다른 글
| 메모리의 구조 (0) | 2022.04.17 |
|---|---|
| [컴퓨터구조] Virtual Memory (0) | 2021.11.25 |
| [컴퓨터구조] Cache Memory - Set Associative Cache (0) | 2021.11.21 |