

mysql에 이어 두 번째 데이터베이스 익히기
Redis
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker
redis.io
NoSQL
'데이터베이스에는 관계형 데이터베이스(RDBMS) 이외에도 여러가지 형태의 데이터베이스가 존재한다' 라고 데이터베이스 전공수업때 배운 적이 있다. 지금까지 내가 써온 Mysql은 관계형 데이터베이스(RDBMS)의 대표적인 예시로, SQL이라고 불리는 쿼리에 의해 저장되며, 모든 데이터는 정해진(정적) 스키마에 맞추어 테이블 형태로 저장되며, 테이블은 열과 행으로 구성되어 관계를 표현한다.
NoSQL은 "Not Only" SQL이라는 뜻이다. 데이터베이스의 활용도가 늘어남에 따라 자연스럽게 데이터량과 트래픽은 증가하게 되는데, 이를 감당하기 위한 Scale-up은 리소스가 많이 들어간다는 단점을 가진다. 예를 들어 MySQL만을 사용하던 시스템이 DB가 감당할 수 있는 양 이상의 트래픽을 받아 timeout이 발생하는 등의 오류가 발생한다고 가정하자. 이와 같은 상황에서 선택할 수 있는 해결책은 2가지정도가 있다.
방법 1. 서비스를 중단하고, 서버에 더 많은 메모리와 CPU를 증설한 뒤 서비스를 재시작한다.
방법 2. 서비스를 중단하고, 더 나은 성능을 가진 새로운 서버를 가져와서 데이터를 옮긴다음 서비스를 재시작한다.
두 가지 방법 모두 서버 성능의 향상을 위해서는 서비스의 중단이 뒤따른다는 문제가 있다. 또한 하나의 장비는 반드시 물리적인 성능 한계를 가질 수 밖에 없고, 그때마다 서비스를 중단하고 교체해주어야 된다는 해결할 수 없는 근본적인 문제가 존재한다.
그래서 일반적으로 Scale-up 대신 Scale-out하는 방식으로 업그레이드 하기 위한 목적으로 NoSQL이 많이 사용되고 있다. 유명한 NoSQL로는 MongoDB, Redis 등이 있는데, 이러한 NoSQL Database들은 다양한 형태의 저장 기술을 지원하여 RDBMS의 특징인 '정적인 스키마'에서 벗어나 수평적 확장을 가능하게 한다.
* scale up은 서버 교체 등을 통해서 처리 능력을 향상시키는 것이고, scale out은 서버의 대수를 늘리는 등 수평적인 확장을 통해서 처리능력을 향상시키는 방식이다.
CAP theory
CAP이라는 이론이 있다. 간단하게 정리하면 "분산 컴퓨터 시스템에서 일관성(Consistency), 가용성(Availability), 분산 허용(Partitioning Tolerance)의 3가지 특징중 최대 2가지만 지원할 수 있다" 라는 내용이다. 분산 컴퓨터 시스템이란 다중 시스템 환경에서 소프트웨어가 작동하는 것을 말한다.
- 일관성(Consistency): 여러 하드웨어에서 같은 시간에 조회하는 데이터는 동일한 데이터임을 보증해야 한다.
- 가용성(Availability): 클러스터링된 노드 일부가 실패하더라도 항상 응답이 가능해야 한다.
- 분산 허용(Partitioning Tolerance): 클러스터링 노드 간 네트워크에 에러가 발생하더라도 정상적으로 서비스를 수행해야 한다.
대부분의 NoSQL은 분산 환경에서 동작하도록 설계되어 있다. 따라서 동일한 데이터가 물리적으로 다른 여러 하드웨어에 저장되고 조회된다.
Redis
위에서 설명한 NoSQL 중에서 가장 유명한 dbms중 하나인 redis는 key-value구조의 비정형 데이터를 저장하고 관리하기 위한 in-memory 데이터 구조를 가진 dbms이다. rdbms의 과부하를 방지하기 위한 캐시 서버로 유용하게 사용된다. 메모리에서 데이터를 처리하기에 MySQL보다 월등히 빠른 속도를 가지며, 단순한 key-value의 형태가 아닌, value가 String, Lists, Sorted Sets, Hashes와 같은 다양한 자료구조를 지원한다. 또한 싱글 스레드환경에서 동작하기에 동기화를 신경쓰지 않아도 되지만, keys *와 같이 O(N)의 시간복잡도를 갖는 명령어 사용을 주의해야 한다.
String
redis의 가장 큰 장점중에 하나는 여러가지 자료구조를 지원한다는 사실이다. 가장 먼저 알아볼 자료구조는 String이다. 이름이 String이더라도 Integer, Long과 같은 숫자나 이진 데이터도 저장할 수 있다. (정수, 실수형같은 타입 구분이 없다)
$ set <key> <value>
$ get <key>
$ <value>
$ del <key>
key값은 unique하며, 동일한 key값을 가지는 쌍을 set하면 value값이 업데이트된다. java 라이브러리의 HashMap과 동일해보인다.
Sorted Set

redis의 Sorted Set(zSet)은 정렬된 집합 데이터 구조로, key, member, score라는 3가지 용어가 나온다. zSet또한 key-value형태의 자료구조와 유사한데, member는 key, score는 value를 의미하며 반드시 숫자로 입력해야 한다.
즉 Redis의 zSet에서의 key는 zSet 자체를 의미하며, member와 score가 해당 zSet의 key와 value역할을 하는 것이다.
하나의 zSet에서 member는 unique하며, member값을 통해 O(logN)의 시간복잡도로 score에 접근할 수 있다.
Redis Hash

Redis의 Hash는 위와 같이 하나의 key 아래에 여러개의 field-value쌍이 존재하고 있다. 자바의 HashMap과 유사한데, HashMap에서는 key-value라고 용어를 쓰는데 redis에는 카테고리를 key라고 부르고, 쌍을 field-value라고 하니 혼동하지 말자.
Hash에서 주로 사용하는 명령어는 다음과 같이 HSET, HGET, HGETALL이 있는데, HSET은 hash의 field-value쌍을 설정하는 명령어이고, HGET은 하나의 key 밑에 존재하는 field에 대한 value값을 조회 할 수 있는 명령어이며 HGETALL은 하나의 key밑에 존재하는 모든 field-value쌍을 가져올 수 있다.
아래 예시를 보면 이해가 어렵지 않을 것이다.
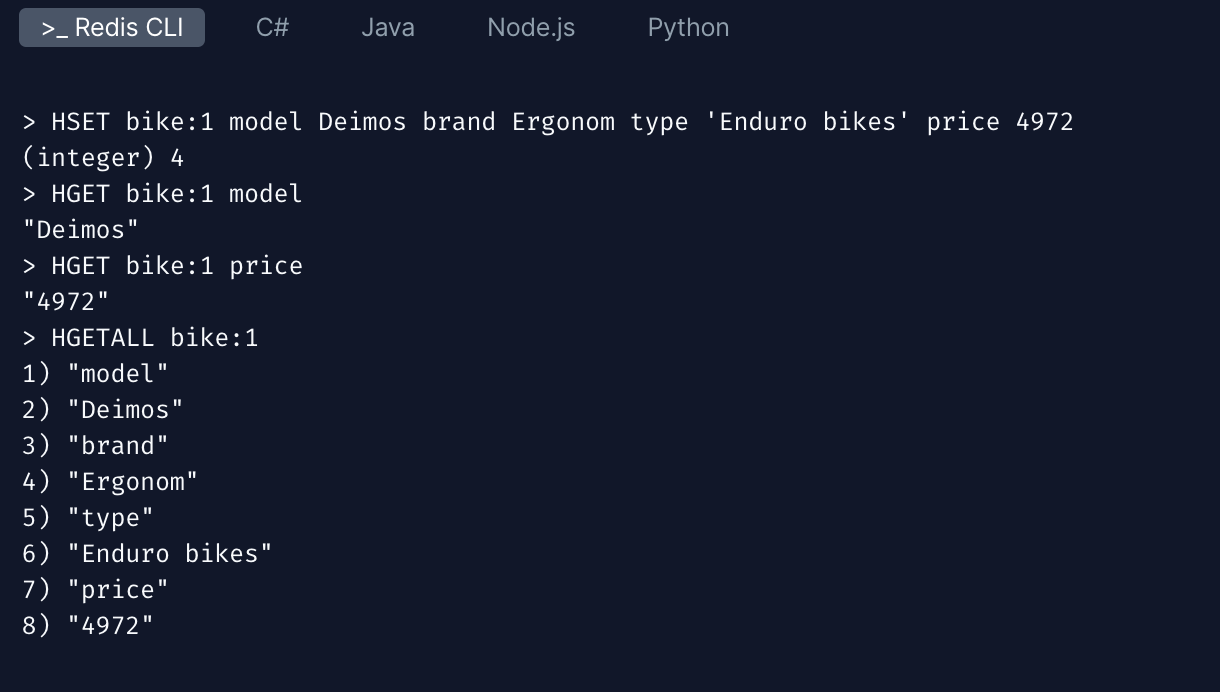
HSET bike:1 model Deimos brand Ergonom type 'Enduro bikes' price 4972
> bike:1이라는 key 밑에
<model : Deimos>, <brand : Ergonom>, <type, 'Enduro bikes'>, <price : 4972> 라는 4개의 field-value쌍이 저장되어 있다.
HGET bike:1 model
> bike:1이라는 key 밑에 있는 model이라는 field에 대응하는 value값을 조회하므로, 'Deimos'가 조회된다.
HGETALL bike:1
> bike:1이라는 key 밑에 저장되어 있는 모든 field-value쌍을 조회한다.
참고
https://redis.io/docs/data-types/hashes/
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=wideeyed&logNo=221428664697
'[ CS기초 ] > 데이터베이스' 카테고리의 다른 글
| [DB] 인덱스(Index)로 조회 성능 개선하기 (1) | 2024.09.26 |
|---|---|
| [DB] SQL문 문법 정리 - DDL (0) | 2023.02.20 |
| [DB] 정규화 (0) | 2023.02.17 |
| [DB] 트랜잭션, 동시성 제어, 락 (0) | 2023.02.08 |
| [DB] SQL문 문법 정리 - DML (0) | 2022.10.12 |